Recently, I had a client who had a relatively fresh AD environment as a result of a divestiture, however, they had stood up their domain controllers at different time periods during the environment build out. As such, their DC’s each had different hardening settings depending on which build they used (and what levels of hardening were applied incrementally over time).
Additionally, they had multiple builds – one for datacenters, one for Oracle Cloud, one for AWS, one for IBM cloud and one for Azure cloud.
So what ended up happening is that their domain member machines were “falling off the domain” (aka NETLOGON 3210):
This computer could not authenticate with \\ORAWADC001.domain.domain.com, a Windows domain controller for domain DOMAIN, and therefore this computer might deny logon requests. This inability to authenticate might be caused by another computer on the same network using the same name or the password for this computer account is not recognized. If this message appears again, contact your system administrator.
My first instinct was to try resetting their computer account password, which you can do locally through NETDOM (see below):
netdom resetpwd /s:server /ud:domain\User /pd:*
[Note: you have to replace server above with the hostname of the machine whose password you are resetting; replace domain and user with your AD credentials that should have the “reset password” privilege delegated in AD; you can type * to give you a password prompt, or alternately, type the password after the colon]
The command succeeded, but the issue still persisted.
I continued to dig around and found NETLOGON 5719 in the event logs of the domain member:
This computer was not able to set up a secure session with a domain controller in domain DOMAIN due to the following:
The remote procedure call failed and did not execute.
This may lead to authentication problems. Make sure that this computer is connected to the network. If the problem persists, please contact your domain administrator.
ADDITIONAL INFO
If this computer is a domain controller for the specified domain, it sets up the secure session to the primary domain controller emulator in the specified domain. Otherwise, this computer sets up the secure session to any domain controller in the specified domain.
So I tested to ensure that the domain controller’s RPC ports were not either being blocked on their local host-based firewall or on a hardware firewall. I also doublechecked that no one had customized their RPC port ranges on the DC’s as companies sometimes do (in an attempt to appease their network/security teams who gasp at the 16,383 ports in the default range since Windows Vista/2008 — previous was just 3985 ports in XP days).
Nope – no one had messed with the DC’s RPC ports… I continued looking in the event log and I see TIME-SERVICE 130:
NtpClient was unable to set a domain peer to use as a time source because of failure in establishing a trust relationship between this computer and the ‘domain.domain.com’ domain in order to securely synchronize time. NtpClient will try again in 15 minutes and double the reattempt interval thereafter. The error was: The trust relationship between this workstation and the primary domain failed. (0x800706FD)
This caused me to start looking up what else could cause these kinds of issues and after spinning my tires searching for information, I decided to try some NLTEST-ing.
nltest /sc_query:domain.domain.com
In return I was getting a weird access denied error:
Flags: 0
Trusted DC Name
Trusted DC Connection Status Status = 5 0x5 ERROR_ACCESS_DENIED
The command completed successfully
Hmm… that’s weird! I tried to reset the connection with
nltest /sc_reset:domain.domain.com
Got a similar access denied error. So I started testing each DC individually, like this:
nltest /sc_reset:domain.domain.com\dc1
nltest /sc_reset:domain.domain.com\dc2
….. etc
What I found was that some domain controllers were accepting the Secure Channel reset/connections and some were not. I noticed also that this was not specific to one physical or cloud location, but rather to individual DC’s.
I began frantically comparing all the local security options under SECPOL, and I noticed a lot of discrepancies (due to incremental and inconsistent hardening efforts in each build that was used). I did fix them, rebooted the DC’s and domain member… still no luck.
So I continued to look through Group Policy and…. nothing. (I will explain why this is important later).
nltest /DBFlag:2080FFFF
It shouldn’t be necessary to restart the netlogon service but you can if you like:
net stop netlogon && net start netlogon
I then re-ran the SC_RESET command on the domain member and checked the logs:
04/25 12:51:49 [MISC] [1876] NetpDcGetName: DOMAIN.COM. using cached information ( NlDcCacheEntry = 0x000002B616463BE0 )
04/25 12:51:49 [MISC] [1876] DsGetDcName: results as follows: DCName:CH03ADC004.DOMAIN.COM DCAddress:\\10.6.2.14 DCAddrType:0x1 DomainName:DOMAIN.COM DnsForestName: Flags:0xe001f1fc DcSiteName:Datacenter-CHI ClientSiteName:Datacenter-CHI
04/25 12:51:49 [MISC] [1876] DsGetDcName function returns 0 (client PID=1052): Dom:(null) Acct:(null) Flags: LDAPONLY BACKGROUND RET_DNS
04/25 12:51:50 [MISC] [612] DsrEnumerateDomainTrusts: Called, Flags = 0x1
04/25 12:51:50 [MISC] [612] DsrEnumerateDomainTrusts: returns: 0
04/25 12:51:54 [CRITICAL] [612] Rejecting an unauthorized RPC call from ncalrpc:TRORAWDFS001.
[Note there were much more logs than this, but it’s pages and pages. It also consists of me rebooting the machine and running nltest /dsgetdc:domain.domain.com – which yields different behavior and thus the logs will show slightly different errors due to different commands run. For those interested, here are the full sanitized logs: https://pastebin.com/j7W0ZVUw ]
Note that the error relates to an “unauthorized RPC call”…. hmmm. I could have sworn I checked all settings in both SECPOL and GPEDIT locally, as well as in AD group policy. But I had not checked the registry key on the domain controllers for RPC security. See, I knew it had to do with security hardening! (Which is definitely a good thing, when properly documented and tested rather than just ripped and gripped as sadly most security hardening these days is done)
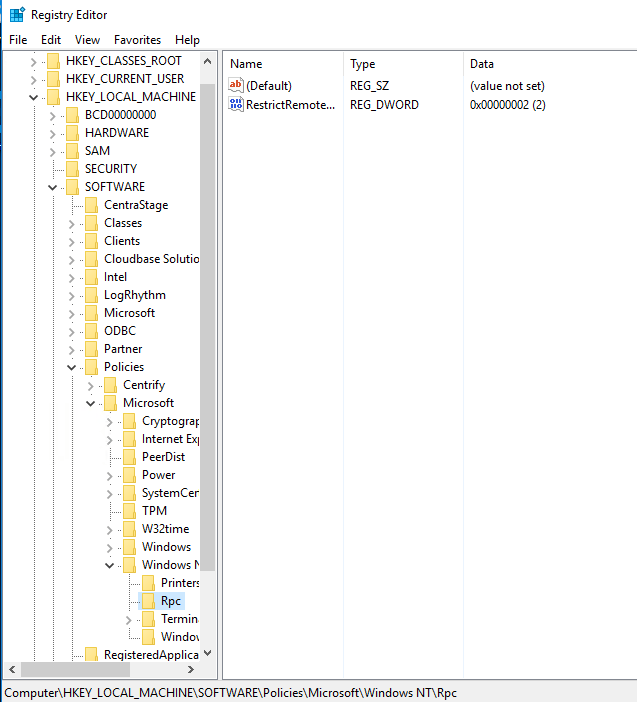
The regkey HKLM:SOFTWARE\Policies\Microsoft\Windows NT\RPC\RestrictRemoteClients was set to DWORD:0x00000002.
I compared the presence of this Key on all Domain Controllers and found that it was inconsistently set between the servers. So that means someone must have either hardened the machine via RegKeys and it did not leave it’s mark in the local GPEDIT policies *OR* perhaps that had it in local GPEDIT on the machine or possibly a domain based GPO — and then for some reason unlinked the policy — and the setting stuck. I am not exactly sure as I did not test the behavior.
Rather than deleting this regkey which would have fixed the issue, I decided to enable RPC authentication on the client machine itself. I also did it through a domain-based group policy so it can be deployed to all domain members (including the DC’s).
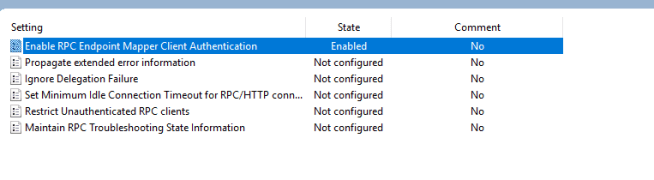
The setting is Enable RPC Endpoint Mapper Client Authentication – which unless you set to Enabled, is disabled and thus uses unauthenticated RPC calls (hence why the more hardened DC’s were rejecting the RPC clients’ calls).
I set it to enabled and rebooted – and the issue went away. This way there is no compromise on security! See below for successful Secure Channel reset/connections. Viola! No more NETLOGON 3210, NETLOGON 5719 or TIME-SERVER 130. Issue fixed 🙂
nltest /sc_reset:domain.com
Flags: 30 HAS_IP HAS_TIMESERV
Trusted DC Name \\CH03ADC003.domain.com
Trusted DC Connection Status Status = 0 0x0 NERR_Success
The command completed successfully
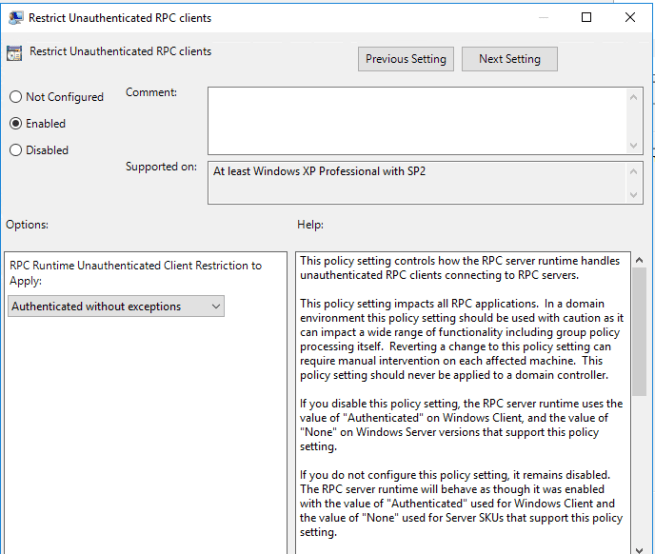
I also went back and added to the domain-based policy a setting for Restrict Unauthenticated RPC clients this way it will ensure that RPC is always authenticated by clients and that RPC servers (whether on a domain controller, domain member server or domain member workstation). So we actually achieved more by hardening the entire domain rather than they had been previously by setting registry keys in the build and on individual servers.
Both the RPC Client and RPC Server authentication security settings are in the same location in Group Policy: Computer > Administrative Templates > System > Remote Prodecure Call
To recap:
Client side settings = “Enable RPC Endpoint Mapper Client Authentication”
Server side settings = “Restrict Unauthenticated RPC Clients”
Also note that RPC is a universal protocol within Windows and used for many things like WinRM, WMI, MMC tools, AD Group Policy processing, MS Exchange, etc. So RPC server settings do not only apply to what we traditionally consider servers, but also to workstations (which would act as an RPC server if you connected via MMC to manage it); additionally, what we traditionally consider to be servers can also be RPC clients (i.e. Exchange Server communicating via RPC to Domain Controller for reading/writing to the directory).
The lesson learned is that BE CAREFUL WHAT YOU DEPLOY IN YOUR BUILDS, LEAVE DOCUMENTATION & MOST IMPORTANTLY FULLY TEST ALL YOUR HARDENING SETTINGS. Turning on a machine and making sure that users can still log in and that the applications still work is not sufficient. If you’re hardening a specific aspect of the environment or protocol, then you need to test the impact on that protocol and whatever applications or mgmt tools (i.e. MMC) rely on it!
[Footnote: Due to the multitude of symptoms involved, my client and I spent wayyyy to long troubleshooting this as we kept getting sidetracked on everything from DNS to NTP — and found many other anomalies along the way that also had to be remediated and brought in line with what the standards should have been along. Be careful to set standards from the get go and ensure all parties are on board for configuring everything from network devices to windows and linux machines — and always be careful with changes to your builds!]

I’m having an issue with a Windows 7 domain joined PC that is 90% in line with what you wrote about, it can’t process group policy updates because it says it can’t resolve user and computer name, getting NETLOGON 3210 event IDs and “ERROR_ACCESS_DENIED” when I try to run nltest /sc_reset:domain.com. It’s a long story why they’re using Windows 7, basically they have to run proprietary hardware via drivers that are only compatible with Windows 7 right now.
I did enable RPC Endpoint Mapper client on the PC, and I do not see the registry entry at all for RPC on the domain controllers. After rebooting the PC, it still is acting the same. When I went to deploy a group policy to the DC’s to “restrict unautheticated RPC clients” it had warnings that the policy should never be applied to a domain controller, so I’m a little confused on how to proceed.
LikeLike
Hi Will, have you tried resetting the trust relationship / machine pwd. with NETDOM? That might help especially if system cannot resolve itself against a DC
LikeLike
It’s Windows 7 and so it doesn’t have netdom. If I reset the machine in AD, at the next reboot, it says it’s lost its trust relationship with the domain.
LikeLike
You should be able to copy it from MS or copy it from a server 2008 machine
LikeLike
Here is a link I found. I haven’t open the file to verify myself so you’ll have to check to make sure it’s safe: https://nolabnoparty.com/en/trust-relationship-failed-workstation-domain/
LikeLike